Revamped De-duplication: Smarter, Faster, and More Flexible
The de-duplication process in EasySLR has been significantly enhanced to deliver more accurate and reliable results. Duplicate detection is now powered by intelligent matching across multiple key fields, such as Title, DOI, Authors, and more, ensuring cleaner datasets with greater confidence.
Users can now customise de-duplication criteria by selecting the specific fields used for duplicate identification. This allows greater control over how duplicates are identified, based on the needs of each project.
Performance has also been optimised, enabling faster processing even for large datasets, so de-duplication remains efficient without compromising accuracy.
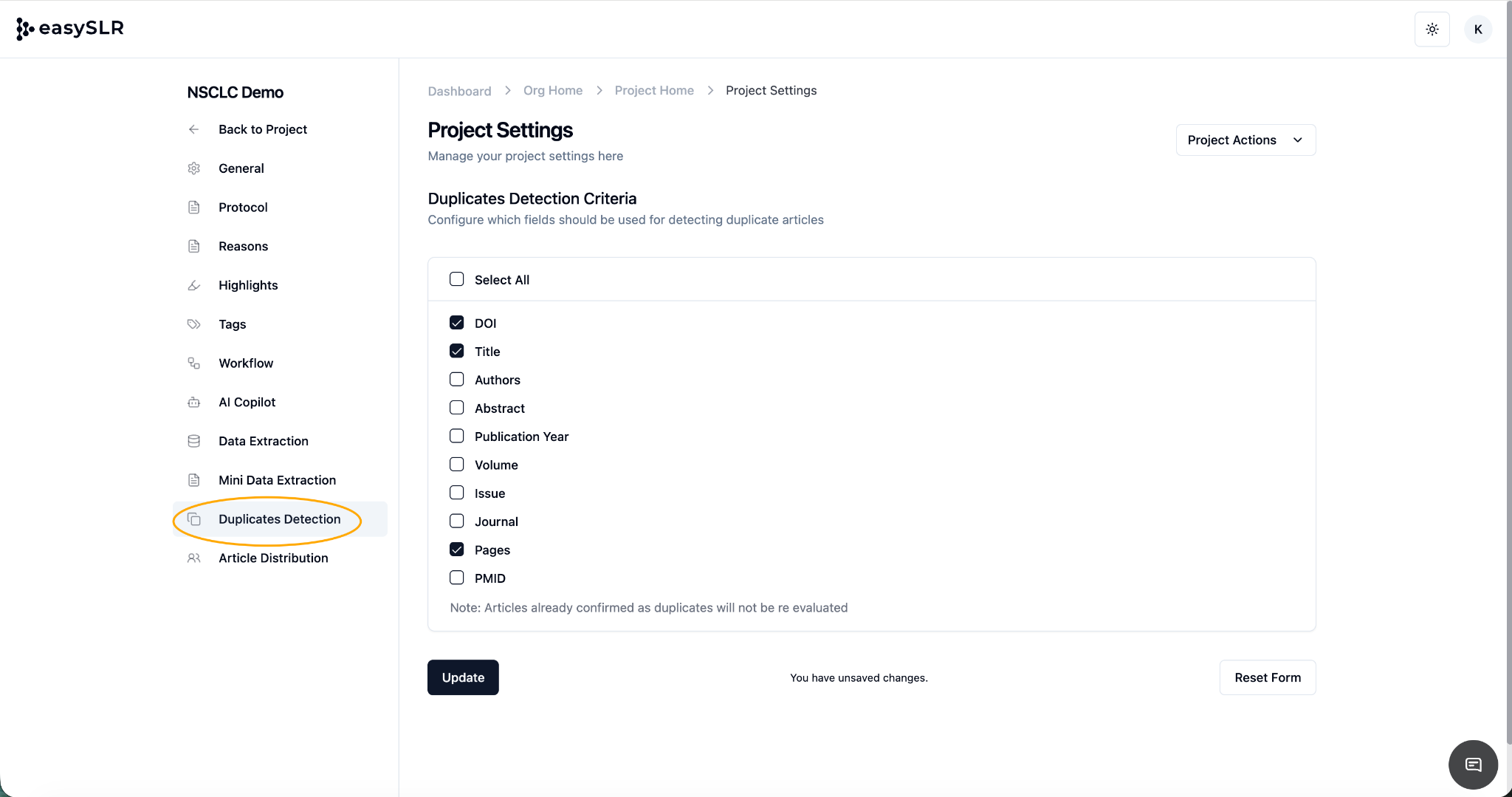
Available fields for duplicate identification include:
DOI (Digital Object Identifier): Detects articles sharing the same DOI
Title: Detects articles with identical titles
Authors: Matches records based on matching authors
Abstract: Identifies articles with similar abstract
Publication Year: Matches articles published in the same year
Volume: Matches records based on the journal volume number
Issue: Matches records based on the journal issue number
Journal: Identifies articles published in the same journal
Pages: Matches articles with identical page numbers
PMID: Detects duplicates using the PubMed ID